The 6 Best LLM Tools To Run Models Locally



Running large language models (LLMs) like ChatGPT and Claude usually involves sending data to servers managed by OpenAI and other AI model providers. While these services are secure, some businesses prefer to keep their data entirely offline for greater privacy.
This article covers the top six tools developers can use to run and test LLMs locally, ensuring their data never leaves their devices, similar to how end-to-end encryption protects privacy.
Why Use Local LLMs?
A tool like LM Studio does not collect user data or track users' actions when they use it to run local LLMs. It lets all your chat data stay on your local machine without sharing with an AI/ML server.
Privacy: You can prompt local LLMs in a multi-turn manner without your prompt data leaving your localhost.
Customization Options: Local LLMs provide advanced configurations for CPU threads, temperature, context length, GPU settings, and more. This is similar to OpenAI’s playground.
Support and Security: They provide similar support and security as OpenAI or Claude.
Subscription and Cost: These tools are free to use and they do not require monthly subscription. For cloud services like OpenAI, each API request requires payment. Local LLMs help to save money since there are no monthly subscriptions.
Offline Support: You can load and connect with large language models while offline.
Connectivity: Sometimes, connecting to a cloud service like OpenAI may result in poor signal and connection.
Top Six and Free Local LLM Tools
Depending on your specific use case, there are several offline LLM applications you can choose. Some of these tools are completely free for personal and commercial use. Others may require sending them a request for business use. There are several local LLM tools available for Mac, Windows, and Linux. The following are the six best tools you can pick from.
1. LM Studio
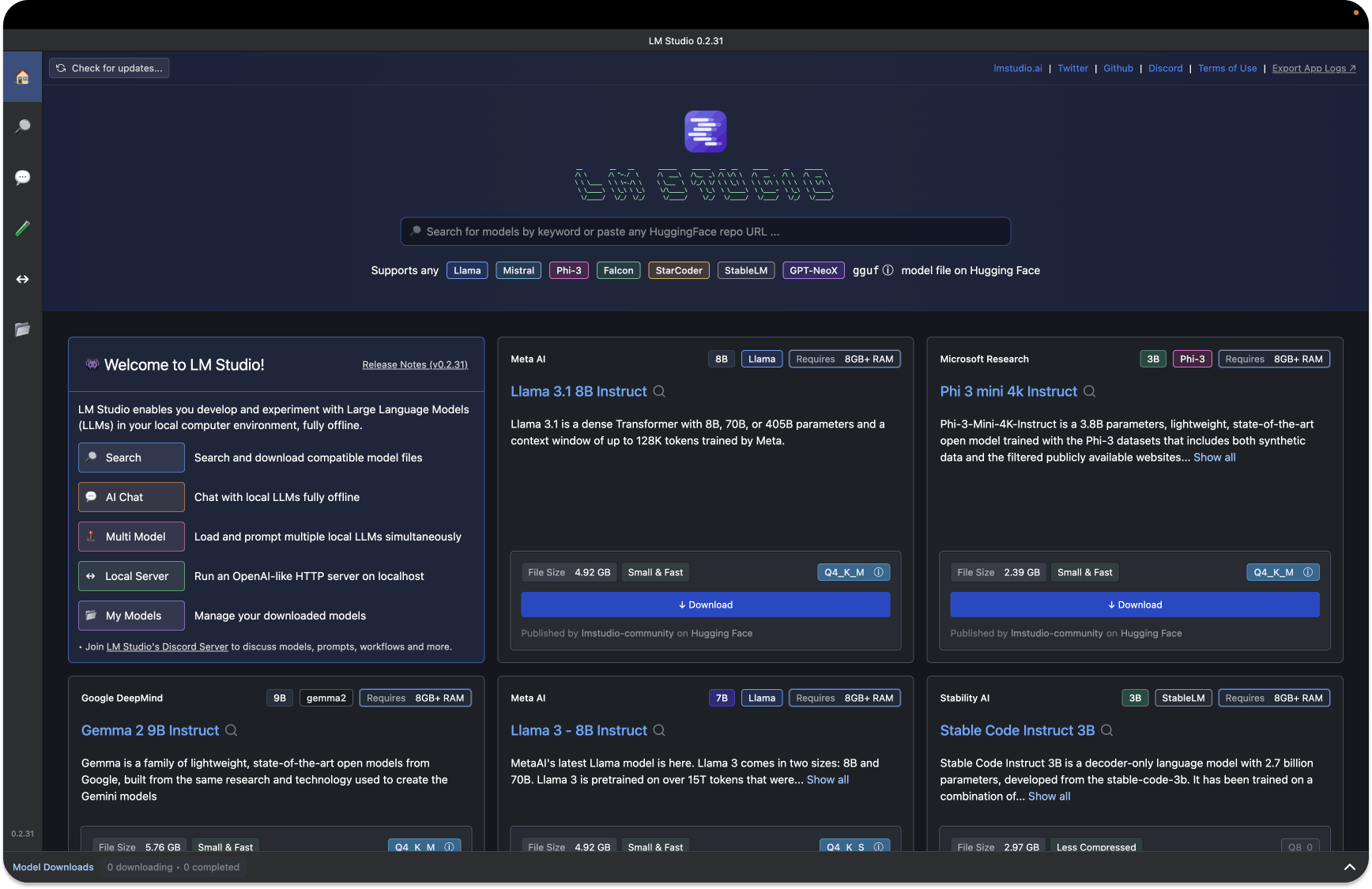
LM Studio can run any model file with the format gguf. It supports gguf files from model providers such as Llama 3.1, Phi 3, Mistral, and Gemma. To use LM Studio, visit the link above and download the app for your machine. Once you launch LM Studio, the homepage presents top LLMs to download and test. There is also a search bar to filter and download specific models from different AI providers.
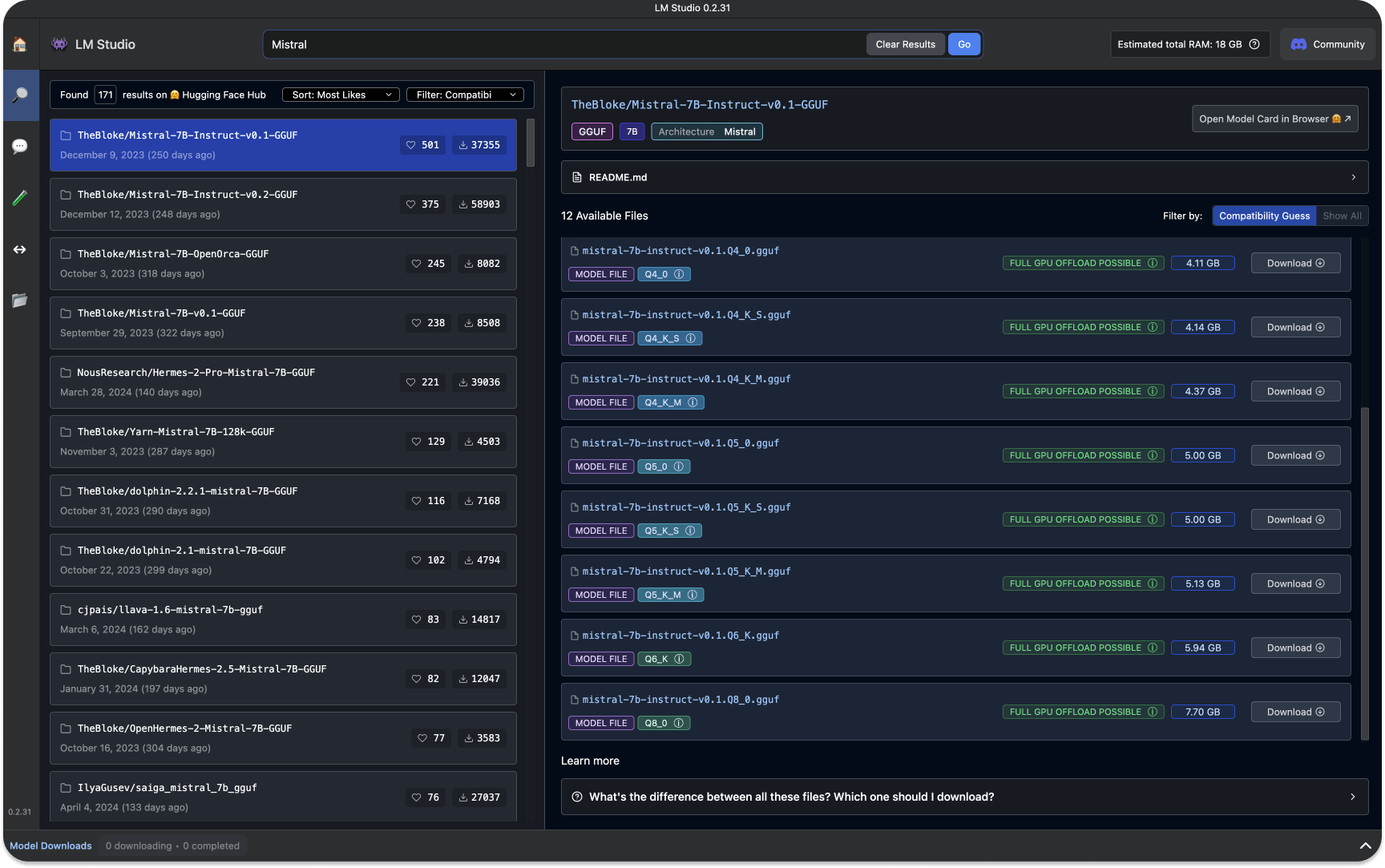
Searching for a model from a specific company presents several models, ranging from small to large quantization. Depending on your machine, LM Studio uses a compatibility guess to highlight the model that will work on that machine or platform.
Key Features of LM Studio
LM Studio provides similar functionalities and features as ChatGPT. It has several functions. The following highlights the key features of LM Studio.
Model Parameters Customization: This allows you to adjust temperature, maximum tokens, frequency penalty, and more.
Chat History: Allows you to save prompts for later use. Parameters and UI Hinting: You can hover on info buttons to lookup model parameters and terms.
Cross-platform: LM Studio is available on Linux, Mac, and Windows operating systems.
Machine Specification Check: LM studio checks computer specifications like GPU and memory and reports on compatible models. This prevents downloading a model that might not work on a specific machine.
AI Chat and Playground: Chat with a large language model in a multi-turn chat format and experiment with multiple LLMs by loading them concurrently.
Local Inference Server for Developers: Allows developers to set up a local HTTP server similar to OpenAI’s API.
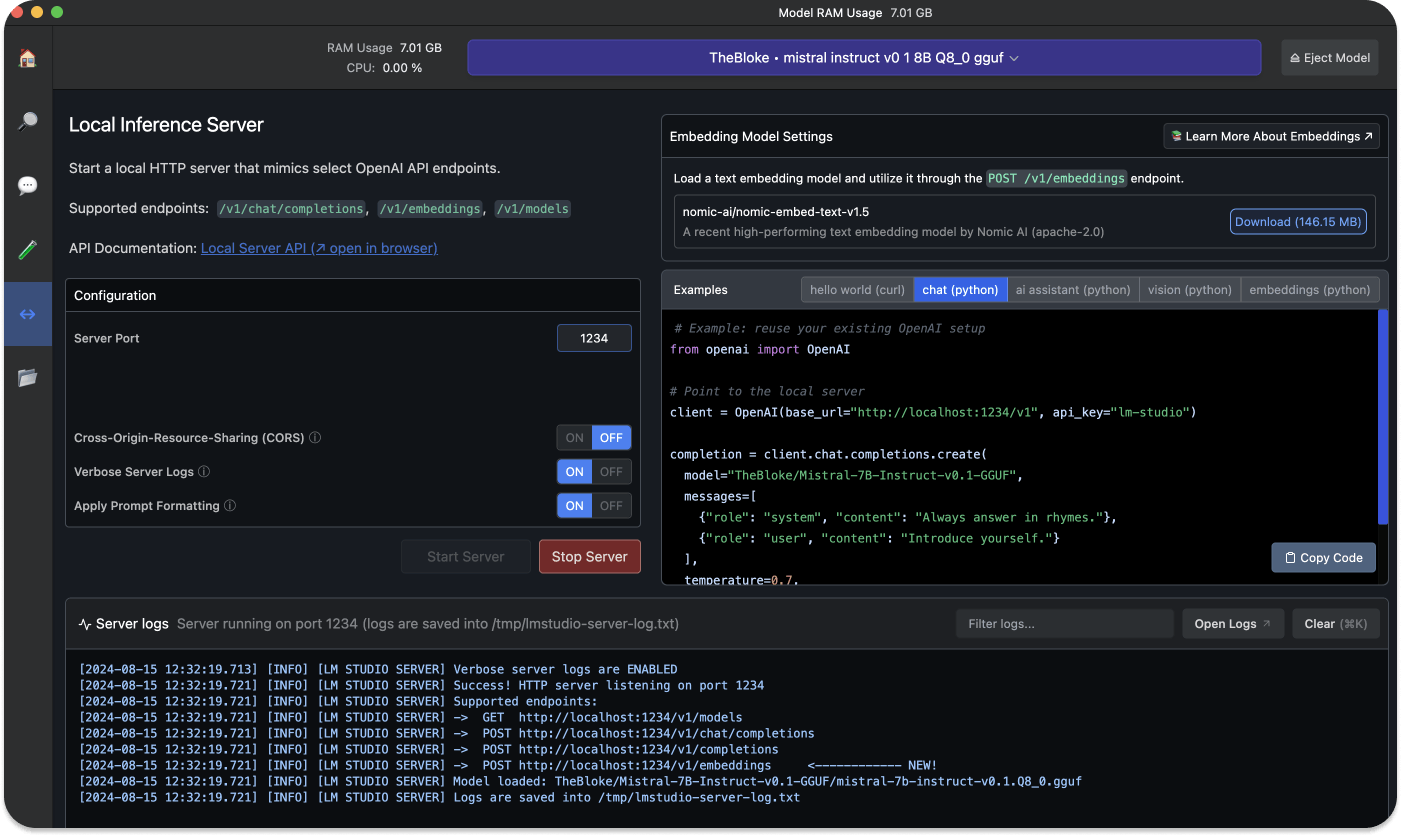
The local server provides sample Curl and Python client requests. This feature helps to build an AI application using LM Studio to access a particular LLM.
# Example: reuse your existing OpenAI setup
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.chat.completions.create(
model="TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)
With the above sample Python code, you can reuse an existing OpenAI configuration and modify the base url to point to your localhost.
OpenAI’s Python Library Import: LM Studio allows developers to import the OpenAI Python library and point the base URL to a local server (localhost).
Multi-model Session: Use a single prompt and select multiple models to evaluate.
Benefits of Using LM Studio
This tool is free for personal use and it allows developers to run LLMs through an in-app chat UI and playground. It provides a gorgeous and easy to use interface with filters and supports connecting to OpenAI's Python library without the need for an API key. Companies and businesses can use LM studio on request. However it requires a M1/M2/M3 Mac or higher, or a Windows PC with a processor that supports AVX2. Intel and AMD users are limited to using the Vulkan inference engine in v0.2.31.
2. Jan
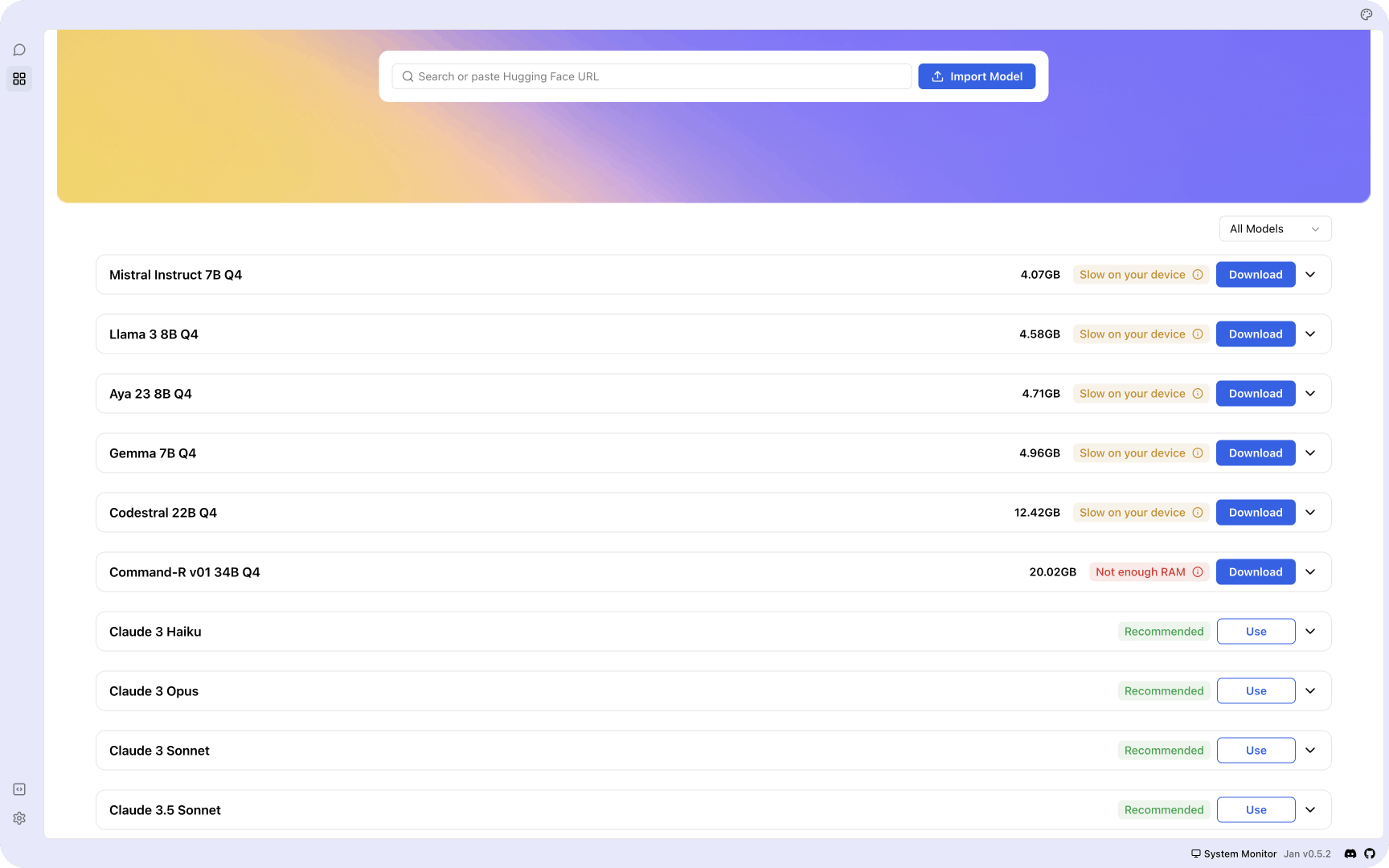
Think of Jan as an open-source version of ChatGPT designed to operate offline. It is built by a community of users with a user-owned philosophy. Jan allows you to run popular models like Mistral or Llama on your device without connecting it to the internet. With Jan, you can access remote APIs like OpenAI and Groq.
Key Features of Jan
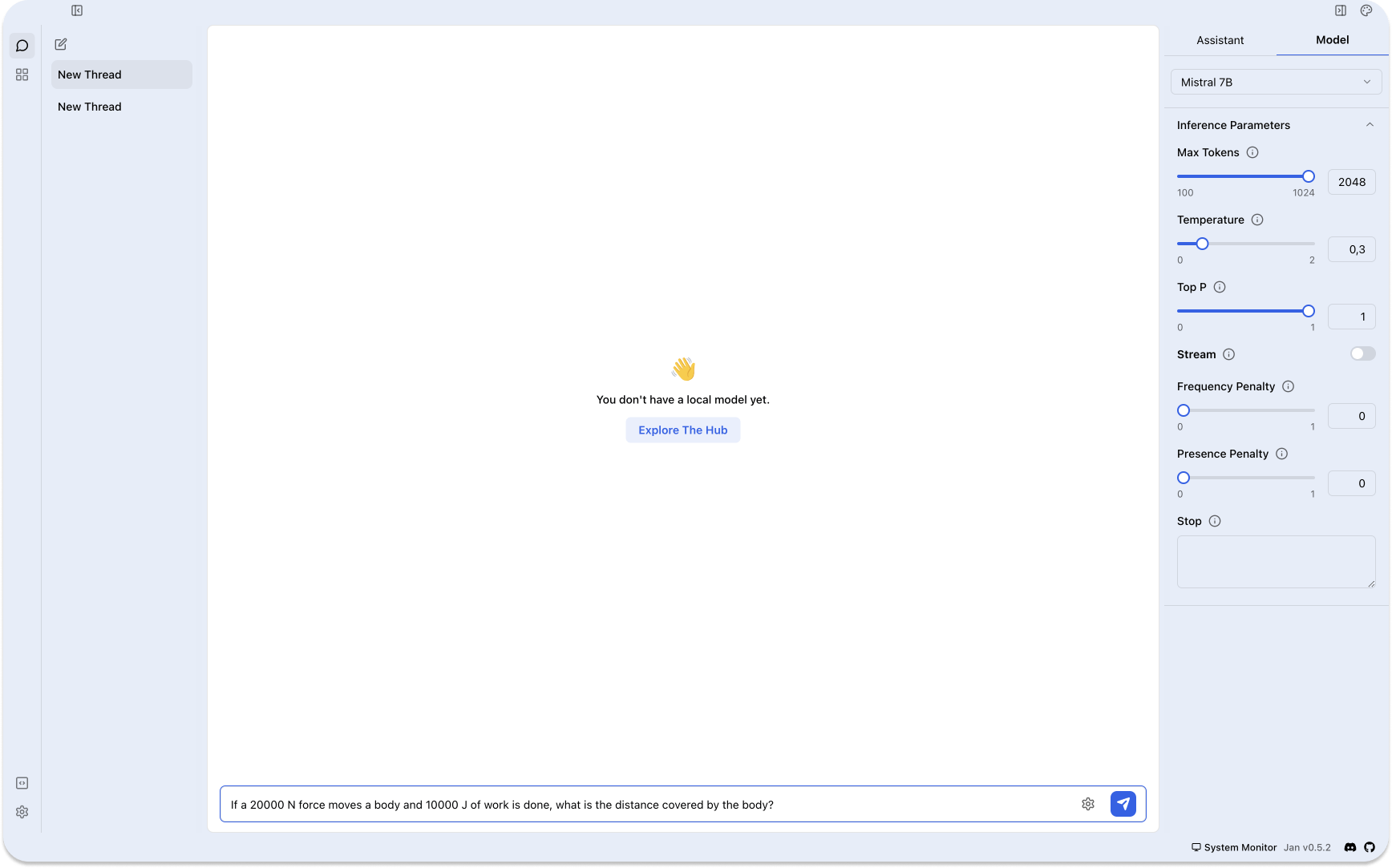
Jan is an electron app with features similar to LM Studio. It makes AI open and accessible to all by turning consumer machines into AI computers. Since it is an open source project, developers can contribute to it and extend its functionalities. The following breaks down the major features of Jan.
Local: You can run your preferred AI models on devices without connecting them to the internet.
Ready to Use Models: After downloading Jan, you get a set of already installed models to start. There is also a possibility to search for specific models.
Model Import: It supports importing models from sources like Hugging Face.
Free, Cross-Platform and Open Source: Jan is 100% free, open source, and works on Mac, Windows, and Linux.
Customize Inference Parameters: Adjust model parameters such as Maximum token, temperature, stream, frequency penalty, and more. All preferences, model usage, and settings stay locally on your computer.
Extensions: Jan supports extensions like TensortRT and Inference Nitro for customizing and enhancing your AI models.
Benefits of Using Jan
Jan provides a clean and simple interface to interact with LLMs and it keeps all your data and processing information locally. It has over seventy large language models already installed for you to use. The availability of these ready-to-use models makes it easy to connect and interact with remote APIs like OpenAI and Mistral. Jan also has a great GitHub, Discord, and Hugging Face communities to follow and ask for help. However, like all the LLM tools, the models work faster on Apple Silicon Macs than on Intel ones.
3. Llamafile
Llamafile is backed by Mozilla whose aim is to support and make open source AI accessible to everyone using a fast CPU inference with no network access. It converts LLMs into multi-platform Executable Linkable Format (ELF). It provides one of the best options to integrate AI into applications by allowing you to run LLMs with just a single executable file.
How Llamafile Works
It is designed to convert weights into several executable programs that require no installation to run on architectures such as Windows, MacOS, Linux, Intel, ARM, FreeBSD, and more. Under the hood, Llamafile uses tinyBLAST to run on OSs like Windows without requiring an SDK.
Key Features of Llamafile
Executable File: Unlike other LLM tools like LM Studio and Jan, Llamafile requires only one executable file to run LLMs.
Use Existing Models: Llamafile supports using existing models tools like Ollama and LM Studio.
Access or Make Models: You can access popular LLMs from OpenAI, Mistral, Groq, and more. It also provides support for creating models from scratch.
Model File Conversion: You can convert the file format of many popular LLMs, for example,
.ggufinto.llamafilewith a single command.
llamafile-convert mistral-7b.gguf
Get Started With Llamafile
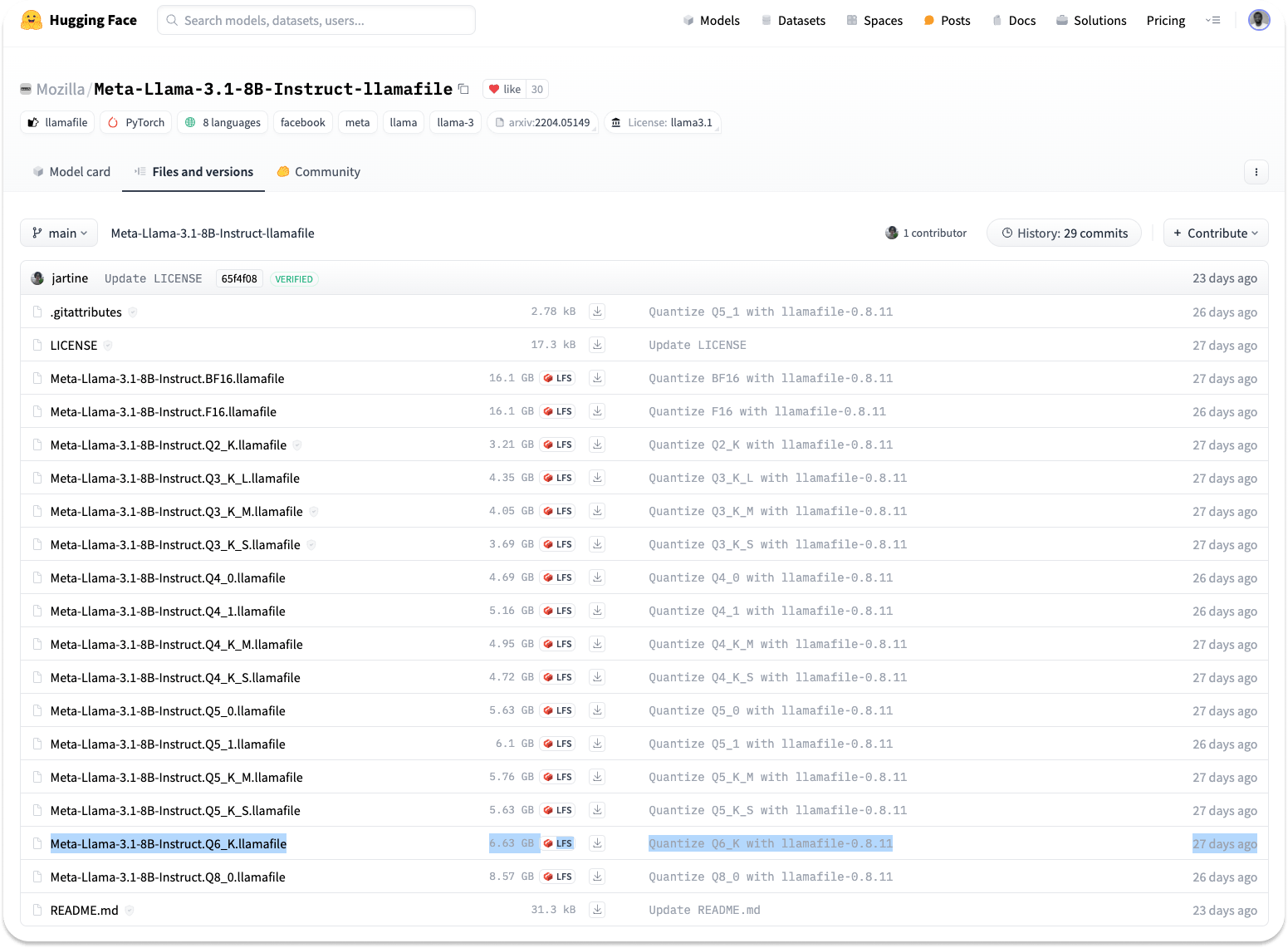
To install Llamafile, head to the Huggingface website, select Models from the navigation, and search for Llamafile. You can also install your preferred quantized version from the URL below.
https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/tree/main
Note: The larger the quantization number, the better the response. As highlighted in the image above, this article uses Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile where Q6 represents the quantization number.
Step 1: Download Llamafile
From the link above, click any of the download buttons to get your preferred version. If you have the wget utility installed on your machine, you can download Llamafile with the command below.
You should replace the URL with the version you like.
Step 2: Make Llamafile Executable
After downloading a particular version of Llamafile, you should make it executable using the following command by navigating to the file’s location.
chmod +x Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
Step 3: Run Llamafile
Prepend a period and forward slash ./ to the file name to launch Llamafile.
./Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
The Llamafile app will now be available at http://127.0.0.1:8080 to run your various LLMs.
Benefits of Using Llamafile
Llamafile helps to democratize AI and ML by making LLMs easily reachable to consumer CPUs. As compared to other local LLM apps like Llama.cpp, Llamafile gives the fastest prompt processing experience and better performance on gaming computers. Since it has a faster performance, it is an excellent option for summarizing long text and large documents. It runs 100% offline and privately, so users do not share their data to any AI server or API. Machine Learning communities like Hugging Face supports the Llamafile format, making it easy to search for Llamafile related models. It also has a great open source community that develops and extends it further.
4. GPT4ALL
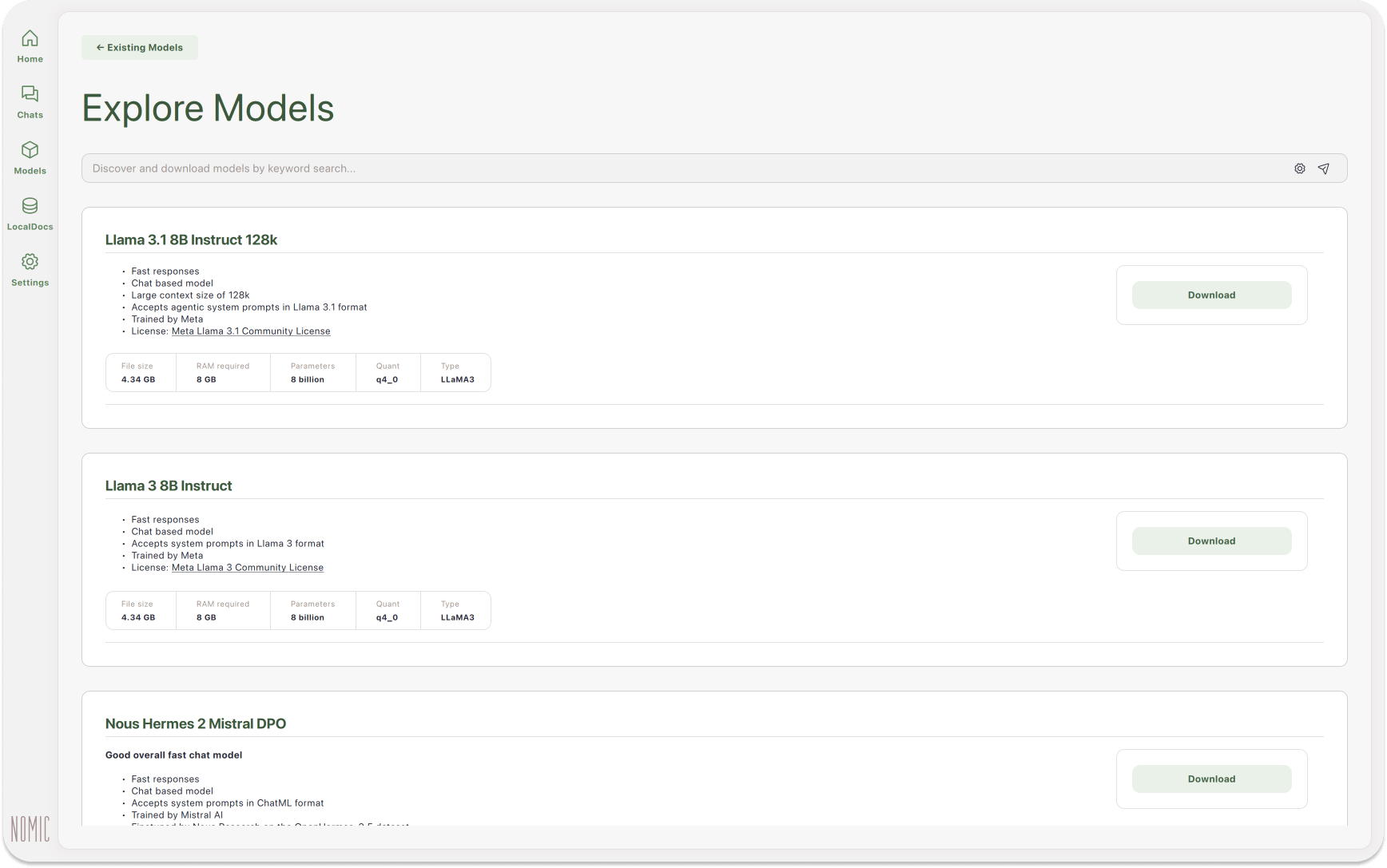
GPT4ALL is built upon privacy, security, and no internet-required principles. Users can install it on Mac, Windows, and Ubuntu. Compared to Jan or LM Studio, GPT4ALL has more monthly downloads, GitHub Stars, and active users.
Key Features of GPT4ALL
GPT4All can run LLMs on major consumer hardware such as Mac M-Series chips, AMD and NVIDIA GPUs. The following are its key features.
Privacy First: Keep private and sensitive chat information and prompts only on your machine.
No Internet Required: It works completely offline.
Models Exploration: This feature allows developers to browse and download different kinds of LLMs to experiment with. You can select about 1000 open-source language models from popular options like LLama, Mistral, and more.
Local Documents: You can let your local LLM access your sensitive data with local documents like
.pdfand.txtwithout data leaving your device and without a network.Customization options: It provides several chatbot adjustment options like temperature, batch size, context length, etc.
Enterprise Edition: GPT4ALL provides an enterprise package with security, support, and per-device licenses to bring local AI to businesses.
Get Started With GPT4All
To start using GPT4All to run LLMs locally, Download the required version for your operating system.
Benefits of Using GPT4ALL
With the exception of Ollama, GPT4ALL has the most significant number of GitHub contributors and about 250000 monthly active users (according to https://www.nomic.ai/gpt4all) and compared to its competitors. The app collects anonymous user data about usage analytics and chat sharing. However, users have the options to opt in or out. Using GPT4ALL, developers benefit from its large user base, GitHub, and Discord communities.
5. Ollama
Using Ollama, you can easily create local chatbots without connecting to an API like OpenAI. Since everything runs locally, you do not need to pay for any subscription or API calls.
Key Features of Ollama
Model Customization: Ollama allows you to convert
.ggufmodel files and run them withollama run modelname.Model Library: Ollama has a large collection of models to try at ollama.com/library.
Import Models: Ollama supports importing models from PyTorch.
Community Integrations: Ollama integrates seamlessly into web and desktop applications like, Ollama-SwiftUI, HTML UI, Dify.ai, and more.
Database Connection: Ollama supports several data platforms.
Mobile Integration: A SwiftUI app like Enchanted brings Ollama to iOS, macOS, and visionOS. Maid is also a cross-platform Flutter app that interfaces with
.ggufmodel files locally.
Get Started With Ollama
To use Ollama for the first time, visit https://ollama.com and download the version for your machine. You can install it on Mac, Linux, or Windows. Once you install Ollama, you can check its detailed information in Terminal with the following command.
ollama
To run a particular LLM, you should download it with:
ollama pull modelname, where modelname is the name of the model you want to install. Checkout Ollama on GitHub for some example models to download. The pull command is also used for updating a model. Once it is used, only the difference will be fetched.
After downloading for example, llama3.1, running ollama run llama3.1 in the command line launches the model.

In the above example, we prompt the llama3.1 model to solve a Physics work and energy question.
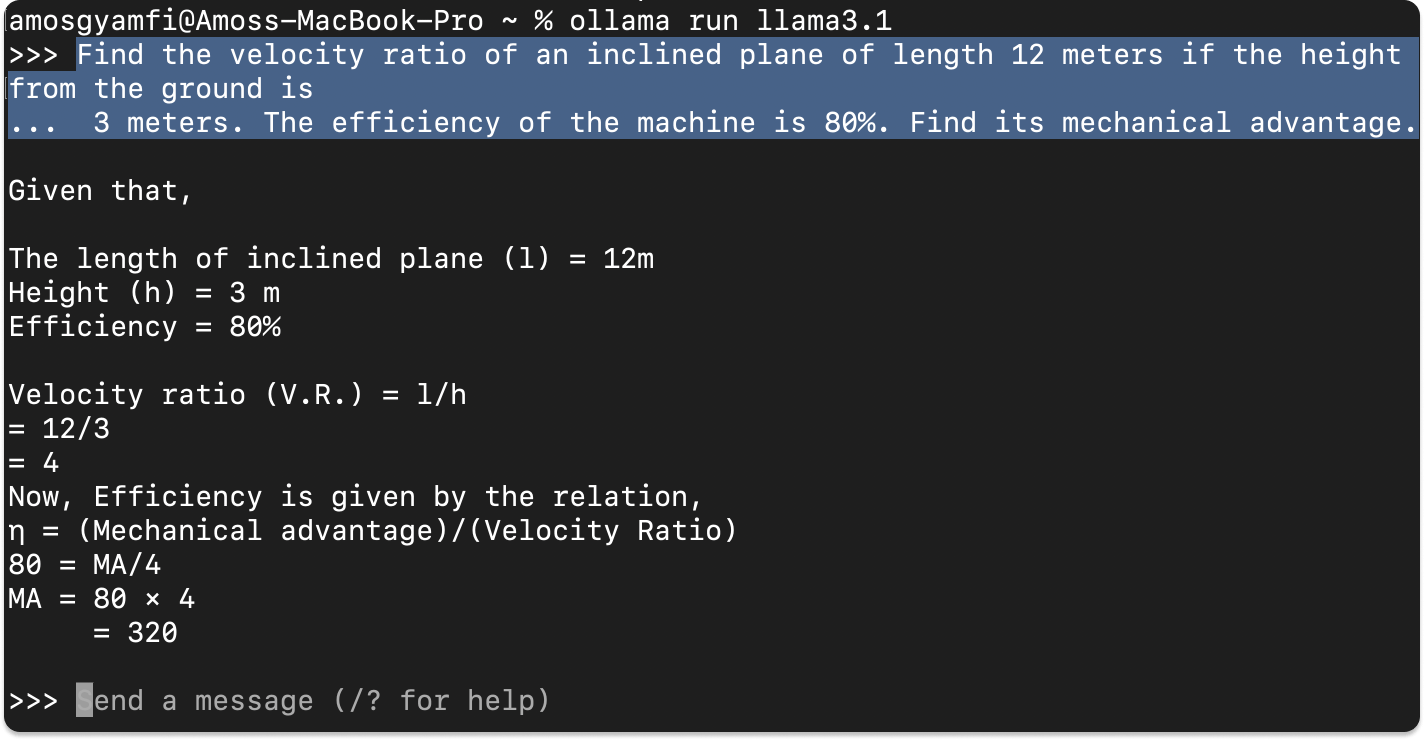
Benefits of Using Ollama
Ollama has over 200 contributors on GitHub with active updates. It has the largest number of contributors and is more extendable among the other open-source LLM tools discussed above.
6. LLaMa.cpp

LLaMa.cpp is the underlying backend technology (inference engine) that powers local LLM tools like Ollama and many others. Llama.cpp supports significant large language model inferences with minimal configuration and excellent local performance on various hardware. It can also run in the cloud.
Key Features of LLaMa.cpp
Setup: It has a minimal setup. You install it with a single command.
Performance: It performs very well on various hardware locally and in the cloud.
Supported Models: It supports popular and major LLMs like Mistral 7B, Mixtral MoE, DBRX, Falcon, and many others.
Frontend AI Tools: LLaMa.cpp supports open-source LLM UI tools like MindWorkAI/AI-Studio (FSL-1.1-MIT), iohub/collama, etc.
Get Started With LLaMa.cpp
To run your first local large language model with llama.cpp, you should install it with:
brew install llama.cpp
Next, download the model you want to run from Hugging Face or any other source. For example, download the model below from Hugging Face and save it somewhere on your machine.
Using your preferred command line tool like Terminal, cd into the location of the .gguf model file you just downloaded and run the following commands.
llama-cli --color \
-m Mistral-7B-Instruct-v0.3.Q4_K_M.ggufb \
-p "Write a short intro about SwiftUI"
In summary, you first invoke the LLaMa CLI tool and set color and other flags. The -m flag specifies the path of the model you want to use. The -p flag specifies the prompt you wish to use to instruct the model.
After running the above command, you will see the result in the following preview.

Local LLMs Use Cases
Running LLMs locally can help developers who want to understand their performance and how they work in detail. Local LLMs can query private documents and technical papers so that information about these documents does not leave the devices used to query them to any cloud AI APIs. Local LLMs are useful in no-internet locations and places where network reception is poor.
In a telehealth setting, local LLMs can sort patient documents without having to upload them to any AI API provider due to privacy concerns.
Evaluating LLMs’ Performance To Run Locally
Knowing the performance of a large language model before using it locally is essential for getting the required responses. There are several ways you can determine the performance of a particular LLM. Here are a few ways.
Training: What dataset is the model trained on?
Fine-tuning: To what extent can the model be customized to perform a specialized task or can it be fine-tuned to for a specific domain?.
Academic Research: Does the LLM have an academic research paper?
To answer the above questions, you can check excellent resources like Hugging Face and Arxiv.org. Also, Open LLm Leaderboard and LMSYS Chatbot Arena provide detailed information and benchmarks for varieties of LLMs.
Local LLM Tools Conclusion
As discussed in this article, several motives exist for choosing and using large language models locally. You can fine-tune a model to perform a specialized task in a telemedicine app if you do not wish to send your dataset over the internet to an AI API provider. Many open-source Graphic User Interface (GUI-based) local LLM tools like LLm Studio and Jan provide intuitive front-end UIs for configuring and experimenting with LLMs without subscription-based services like OpenAI or Claude. You also discovered the various powerful command-line LLM applications like Ollama and LLaMa.cpp that help you run and test models locally and without an internet connection. Check out Stream's AI Chatbot solution to integrate an AI chat into your app and visit all the related links to learn more.